The present article is intended for general educational purposes and is not meant to constitute financial advice to any person. Readers are encouraged to seek financial advice from a qualified professional, and should not rely on this post to make investment decisions. The author does not give any warranty as to the accuracy of the information. This post was written for instructive purposes as an outside work activity. Any opinion or method presented here is my own and does not represent my current employer’s (UBS) views or methods.
A quick introduction to Modern Portfolio Theory
Modern Portfolio Theory (MPT) was developed by Harry Markowitz in the 1950s and become a cornerstone of financial theory, providing a framework for investors to achieve their financial goals while managing risk. This theory was so influential that Markowitz later went on to win a Nobel prize. Let’s quickly recap the key ideas of this theory, which you will see are quite simple.
MPT starts with the fundamental concept that an investor should not focus solely on the potential return of individual investments, but also take into account their risk characteristics. Simply stated, in MPT the goals of the investors is to maximize portfolio returns while minimizing risk. Where risk is measured by the volatility of the returns (standard deviation of returns).
MPT suggests that by combining investments with different risk and return characteristics in a portfolio, investors can achieve a more favorable risk-return tradeoff. The key to achieving an efficient portfolio is diversification. By spreading investments across different asset classes, such as stocks, bonds, and other securities, investors can reduce the overall risk of their portfolio. This is because different assets tend to have varying performance patterns over time. When some investments are declining, others may be rising, helping to offset losses and stabilize overall portfolio returns. Ideally, we want assets in the portfolio to be as uncorrelated as possible.
To construct an optimal portfolios using MPT, we normally use historical data to estimate the expected returns and risk (standard deviation), and correlations of different assets. This information is then used to find out which combination of assets offers the highest expected return for a given level of risk, or equivalently the lowest risk for a desired level of return. As illustrated in the figure below, we could plot the risk-return profile of all possible portfolios. Each dot corresponds to the risk-return profile for a different combination of assets. The portfolios that maximise returns while minimising risk are all the ones along the efficient frontier because for any level of risk (standard deviation), these are the portfolios that offer the highest return.
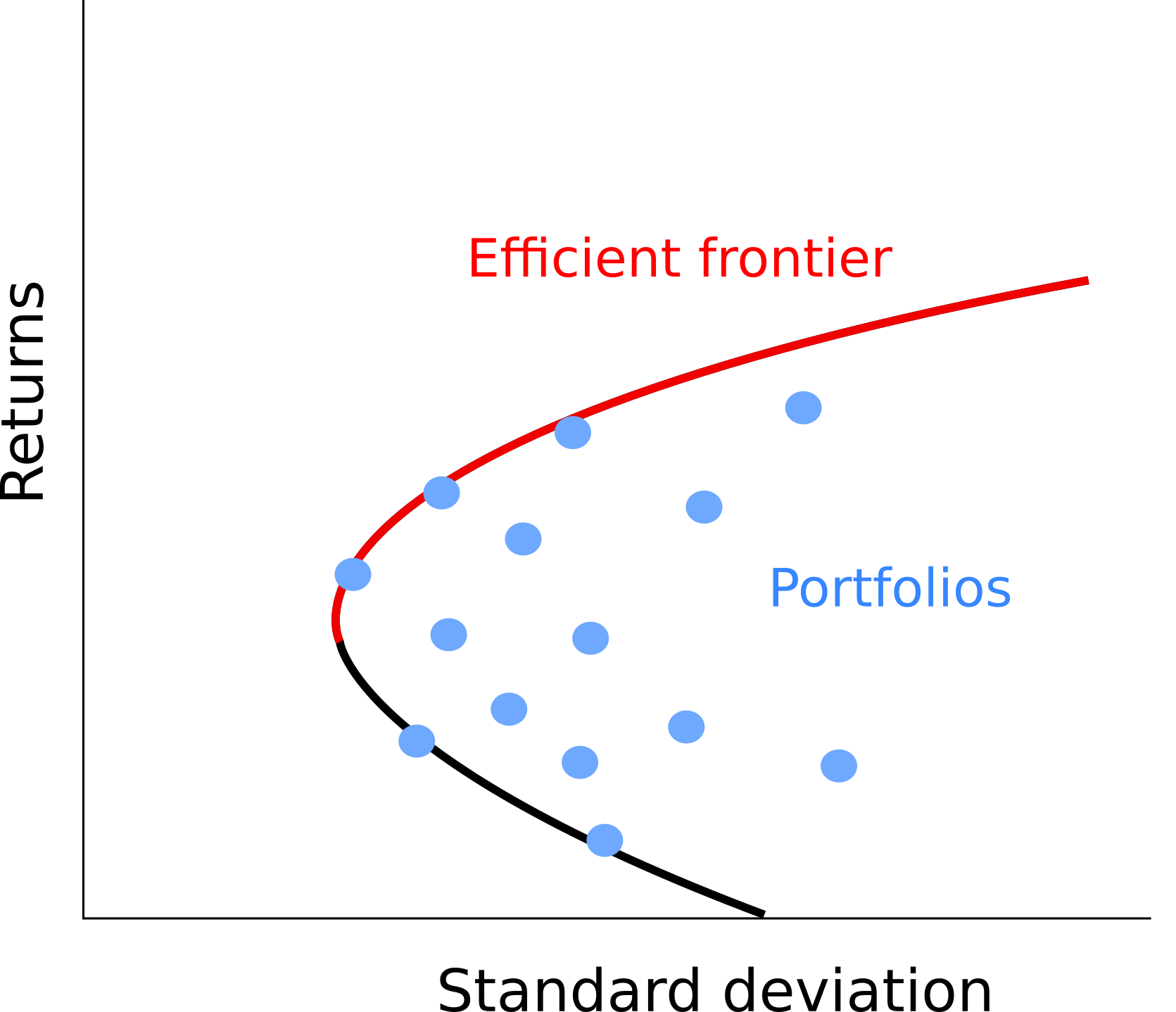
Figure 1: Efficient frontier
The efficient frontier offers a sort of menu for the investor. A hypothetical investor could fix it’s level of desired risk (or return) based on its preference and use the efficient frontier to find out the portfolio combination that best satisfies it’s risk appetite (return appetite).
It’s important to note that MPT has its limitations. It assumes that historical data is a reliable indicator of future performance, which often does not always hold true. Market fluctuations are not modelled in MPT and variance is used to model risk while better measures for downside risk exist. Additionally, it does not take into account any other aspect beside returns and volatility. For instance, knowledge on long term trends and ethical or environmental concerns will not affect the asset selection. That being said, MPT still holds a very important place in finance.
In the next section I will provide a demonstration of how a set of securities can be combines into a more efficient investment allocation according to MPT.
Practical demostration of portfolio optimization
Data for the demonstration
I will use a list of funds from UBS to show how they could be combined to reach a more efficient portfolio. If you wish to follow along, you may download the funds list, and the historical return data here.
The first table (funds) contains a list of all the UBS funds with some basic information, such as:
- name: the name of the fund
- currency: the currency of the fund
- TER: Total Expense Ratio of the fund. This is a measure of the average fees associated with each fund (expressed in percentage).
- ISIN: the ISIN code of the fund. This is a code that uniquely identifies financial products.
- url: url of the swissfunddata.ch page from which the historical return data was downloaded and where more information on the fund can be found.
You can explore this list of funds in the table below.
The second table (prices) contains the historical return data for each fund. The total return data was downloaded from swissfunddata.ch. Total returns is the amount of money an investor would earn if it invested in the fund, it include both changes in price and dividend/coupon payments. I performed some additional cleaning to better compare the returns across different funds. In particular, I calculated the net returns by deducting the total expense ratio (TER) to each fund’s returns (spreading the cost over all the year) and converted all values to a common currency: Swiss Francs (CHF). The data for the daily exchange rates was sourced from yahoo finance. The figure below, shows what this data looks like for the first three funds in the list.
Figure 2: Total returns for the first three funds
Finding an efficient portfolio
The key assumption when we are performing this optimization exercise is that we assume future performance of an asset to be like it’s past performance, at least in the long run. So, for instance, if a stock has been delivering a 2% annual growth over the last ten years, we will assume this trend will continue in the future.
Hence, our first step is to summarise past performance of our candidate funds. There are three metrics which we need to derive: 1) the average returns, 2) the variance of the returns, and 3) the covariance matrix. The average returns is a measure of the fund’s long term trend, the variance measures how strongly the returns fluctuate around this trend, and the covariance matrix captures how different funds tend to move together (their correlation). We will assume these measures will stay fixed in the future.
Calculating the mean, variance and covariance matrix
To calculate the mean, variance and covariance matrix, I start by transforming the fund prices into log returns. In many applications, log returns are more handy to work with because instead of compounding, they can just be added up.
# CALCULATE (DAILY) LOG RETURNS
# initiate an empty table with the dates only
returns <- data.frame("Date" = as.Date(prices$Date))
# Loop over every security and calculate the log returns
for (i in funds$ISIN){
#Add the log returns to our new table
returns[,i] <- log(prices[,i]) - c(NA, log(prices[1:(nrow(prices)-1),i]))
}Now let’s calculate the mean, variance and covariance matrix. This is straightforward in R. Note that we have different data points for each fund. So, some values are calculated over longer periods than others. In the case of the covariance matrix, we use all the data points available for each pair of funds. This may result in a covariance matrix that is not positive semidefinite, which we will see can be an issue for some optimization techniques.
# compute the average daily log returns for every fund and save them in a column vector
x <- matrix(sapply(returns[, colnames(returns) != "Date"], mean, na.rm = T), ncol = 1, nrow = ncol(returns) - 1)
# compute covariance (with pairwise deletion)
covar <- cov(returns[, !(colnames(returns) %in% c("Date", "year"))], use = "pairwise.complete.obs")The plot below summarises the mean/standard deviation for all the funds in our list. It shows the return and volatility we would expect if we were to invest entirely in one asset. However, when creating a portfolio we can combine multiple assets to create a “blend” of returns and risk profiles. In other words, we can position ourselves anywhere between these dots. Moreover, we can use diversification of the portfolio to reduce the risk while keeping the expected return constant. Let’s see how to find an efficient portfolio now.
Figure 3: Risk/return plot for the funds in the example list
Building an optimal portfolio
We can form a portfolio by assigning a weight comprised between 0 and 1 to each asset, such that the sum of all weights add up to 1. Finding the optimal portfolio corresponds to solving a constrained optimization problem, in which we are minimizing variance for any fixed level of return by tuning the weights of each assets (the parameters of the problem). Or equivalently, we can maximize the returns for any given level of variance. The two approaches lead to the same solution. The optimisation problem is further complicated by the addition of limitations on the weights. For instance we might impose that the weights need to be non-negative (i.e. we only allow long positions). A mathematical formulation of our problem would resemble something like this:
\[\begin{aligned} \min_{w} \quad & w^T \mathbf{\Sigma} w\\ \textrm{subject to} \quad & w\mu = \text{r}\\ & w_i \geq 0 \quad \forall i \in \{1, 2, \ldots, n\}\\ & \sum_{i=1}^n w_i = 1 \end{aligned}\]
Where \(w\) is the n-vector of fund weights that we are trying to optimize, \(\mathbf{\Sigma}\) is the covariance matrix we just calculated (covar) and \(\mu\) is the n-vector of average fund daily returns (the x variable in the code snippet of the previous section). The first constraint requires the expected returns from the portfolio to be equal to a desired level \(r\). Finally, the last two lines are just formulating the constraint that the fund weights need to be non-negative and add up to 1.
We will now try three ways of solving this problem: 1) random portfolio simulation. 2) An improved simulation approach. 3) Deriving the solution with convex optimization algorithms.
1) Simulating a large number of random portfolios
An exact solution to the optimization should exist for the problem formulated in this article because it fall neatly into a convex optimization problem (more on this when we describe the 3rd approach). However, in practice, the objective function might not always be convex and it may be hard to find the optimal weights if there are hundreds of assets in the portfolio or if complicated constraints are added to the weights. Also, the optimal solution might be very sensitive to small changes in the inputs. Therefore, a simple approach is to use a simulation to approximate the optimal portfolio. While such an approach might not yield THE EXACT optimal portfolio, it can get close enough and the calculations are straightforward to implement: we just need to calculate the expected portfolio returns and variance for a large number of portfolio combinations.
Here we will try the dumbest possible simulation to see how close we can get: we pick the portfolio weights completely at random. The following graph shows the expected volatility and returns from 200’000 random portfolios in which we fix the maximum number of assets to 10 and only allow long positions (no negative asset weights). The edge of the cloud of simulated portfolio reminds us of the efficient frontier we introduced at the beginning of the post — this is no accident. Below you will find the code to replicate such an experiment.
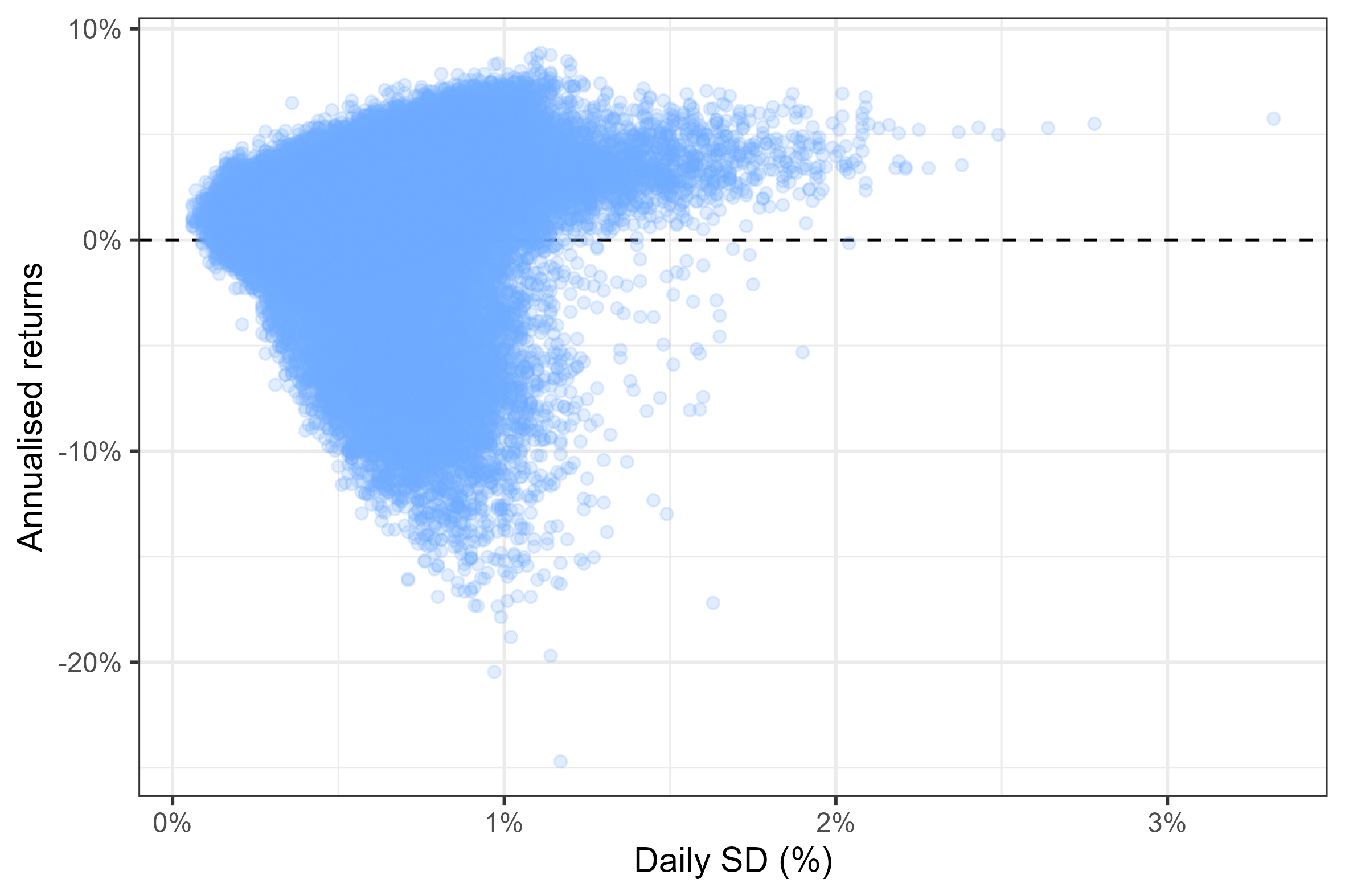
Figure 4: Return/Volatility of 200’000 randomly generated portfolios
sim_random_portfolios <- function(x, # column vector of returns
covar, # covariance matrix
n = 10000, #number of simulations
n_securities = 10){ #limit on the number of assets in the portfolio
# transform returns into a column vector (for matrix multiplication)
x <- matrix(x, ncol = 1)
# initiate table to store portfolio stats
tab <- data.frame(matrix(NA_real_, ncol = 2, nrow = n))
colnames(tab) <- c("returns", "volatility")
# initiate list to store portfolio weights
weights <- list()
# initiate percentage counter
percentage <- 0
# perform simulations
for (i in 1:n){
# random draw for weights
w <- 0
while (all(w==0)){
w <- rep(0, nrow(x))
securities_in_portfolio <- sample(1:nrow(x), size = n_securities, replace = FALSE)
w[securities_in_portfolio] <- runif(n_securities, min = 0, max = 1)
}
# scale back weights to norm 1
w <- w/sum(w)
# save weights
weights[[i]] <- w
# calculate returns and volatility of portfolio
portfolio_sd <- sqrt(t(w) %*% covar %*% w)
portfolio_returns <- t(w) %*% x
# save results in summary table
tab[i,] <- c(portfolio_returns, portfolio_sd)
# Print percentage progress to console
if (round(100*i/n) > percentage) percentage <- round(100*i/n)
cat(paste0("\r Progress:", stringr::str_pad(percentage, width = 3, side = "left", pad = " "), "%"))
}
return(list(summary = tab, weights = weights))
} 2) A more efficient simulation
The simmulation approach we just presented is not very efficient: we are simulating a very large number of portfolios (200000), but most of them are not very good choices, many yield negative expected returns! We can try to concentrate our simulations on portfolios which we think can yield superior return/risk profiles, we will do this by:
Instead of picking asset allocations at random, we will give a higher chance to assets that were present in simulated portfolios with higher sharp ratio (the ratio of returns to volatility). This will slowly push the simulation towards better portfolios.
At each simulation we allow one asset to be introduced completely at random. This ensures we try new combinations of assets, some may be bad, but others might improve the mix.
Every now and then, we completely reset all the sampling probabilities to better explore the different coombinations of assets. This ensures we do not get stuck with a small number of assets and stop exploring other options.
The figure below shows 1000 simulated portfolios. This approach seems to have improved our simulation! Compared to the previous graph, we are spending more time in the upper diagonal, close to the “efficient frontier”.
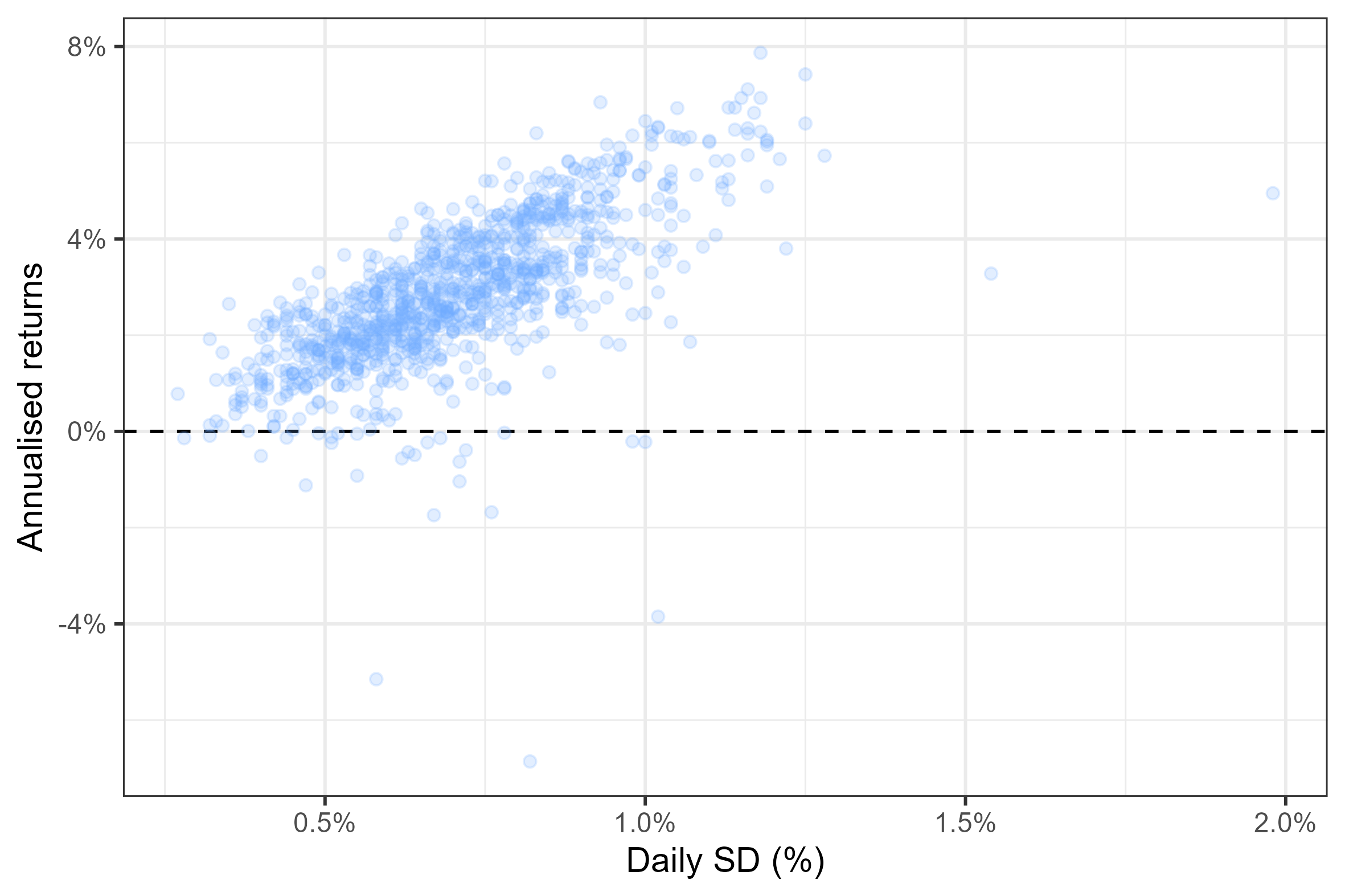
Figure 5: Return/Volatility of 1000 simulated portfolios
sim_improved <- function(x, # vector of returns
covar, # covariance matrix
n = 10000, #number of simulations
n_securities = 6, # number of securities in portfolio
n_resets = 5){ # number of times to reset sampling probs
# transform returns into a column vector (for matrix multiplication)
x <- matrix(x, ncol = 1)
# initiate table to store portfolio stats
tab <- data.frame(matrix(NA_real_, ncol = 2, nrow = n))
colnames(tab) <- c("returns", "volatility")
# initiate list to store portfolio weights
weights <- list()
# initiate percentage counter
percentage <- 0
# initiate storage variables
max_sharpe <- 0
hist_sharpe <- NULL
hist_security_selection <- rep(0, nrow(x))
# perform simulations
for (i in 1:n){
# rest sampling probabilities
if (i %in% c(1, 1:(n_resets - 1) * floor(n/n_resets))){
prob_sec <- rep(1/nrow(x), nrow(x))
}
# random draw of asset weights
w <- 0
while (all(w==0)){
# use sampling prob to select securities in portfolio
securities_in_portfolio <- sample(1:nrow(x), size = n_securities, prob = prob_sec, replace = FALSE)
# replace one of the securities completely at random to explore new space
securities_in_portfolio[1] <- sample(c(1:nrow(x))[!(1:nrow(x) %in% securities_in_portfolio)], size = 1)
# random weights
w <- rep(0, nrow(x))
w[securities_in_portfolio] <- runif(n_securities, min = 0, max = 1)
# keep track of number of times each security is used
hist_security_selection[securities_in_portfolio] <- hist_security_selection[securities_in_portfolio] + 1
}
# scale back weights to norm 1
w <- w/sum(w)
# save weights
weights[[i]] <- w
# calculate returns and volatility of portfolio
portfolio_sd <- sqrt(t(w) %*% covar %*% w)
portfolio_returns <- t(w) %*% x
# save results in summary table
tab[i,] <- c(portfolio_returns, portfolio_sd)
# store adjusted sharpe ratio of current portfolio
sharpe <- portfolio_returns/portfolio_sd
hist_sharpe[i] <- sharpe
# update sampling probability vector if it is the best portfolio
if (sharpe >= max_sharpe){
# update prob vector
prob_sec <- w * as.vector((1 + log((1 + sharpe)/(1 + max_sharpe))))
prob_sec <- prob_sec / sum(prob_sec)
# store current Sharpe ratio as new best
max_sharpe <- sharpe
}
# paste simulation percentage to console
if (round(100*i/n) > percentage) percentage <- round(100*i/n)
cat(paste0("\r Progress:", stringr::str_pad(percentage, width = 3, side = "left", pad = " "), "%"))
}
return(list(summary = tab, weights = weights, hist_sharpe = hist_sharpe, freq_securities = hist_security_selection/n))
} In the figure below, I have plotted a cloud of 10000 simulated portfolios and highlighted in red the portfolios with the highest sharp ratio offering respectively at least: 1%, 2%, … and 8% annual return. You may think of these as options from which a potential investor could pick from.
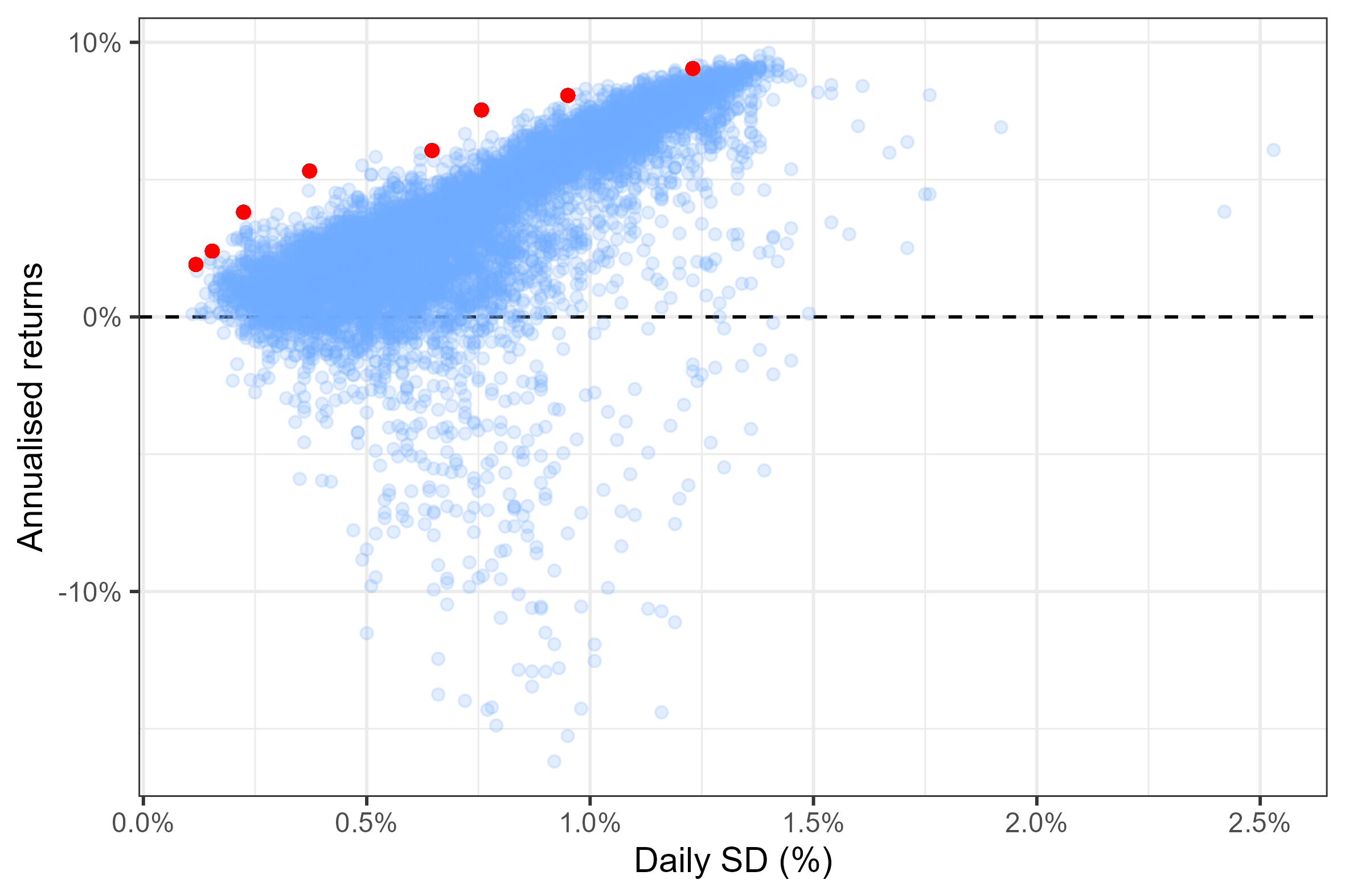
Figure 6: A selection of the most efficient portfolios
Besides the simulated portfolios, our algorithm also provides a way of ranking securities. Since our algorithms tries to find better combinations of assets at each simulation, it is implicitly ranking the assets to find the best one. We can extract the final list of the best securities by looking at the assets that were chosen most often in the simulated portfolios. The list is reported below. A portfolio could be built from these securities.
3) Solving with convex optimization algorithms
Finally, we can try to find the exact optimal solution to our problem. Here I will show you how this can be implemented in R using the package CVXR, a package specifically designed to solve convex optimization problems.
We start by cleaning up a bit the data. We will remove from the list of funds the ones which have too few observations. That’s because we wish to use only complete observations to calculate the covariance matrix. When complete observations are used the covariance matrix will be symmetric and positive semi-definite. This will ensure that our optimization problem is indeed convex and has a solution. Note that the covariance matrix is not necessarily positive semi-definite when it is constructed from pairwise complete observations like we did for the simulation approaches. Finally, we also want to make sure that the returns of the funds are not strictly collinear, which could mess up the calculations.
# create a table which will hold the daily returns for every fund we wish to keep in the analysis
X <- returns[, colnames(returns) != "Date"]
# exclude funds with too little data
for (i in colnames(X)){
if (sum(is.na(X[,i])) > 0.5*nrow(X)){ # check that the number of missing observations does not exceed 50%
X[,i] <- NULL
}
}
# exclude collinear funds (if any)
temp <- cor(X, use = "pairwise") # calculate the correlation between every pair of funds
for (i in colnames(X)){
# remove the fund if it has a correlation of 1 / -1 with any other fund and update the correlation table
if (any(abs(temp[-which(colnames(X) == i), i]) == 1)){
X[,i] <- NULL
temp <- cor(X, use = "pairwise")
}
}Let’s now compute the covariance matrix and the average daily returns for every candidate fund. Note that we need to use "complete.obs" when computing the covariance here. This will compute the covariance only from the days for which we possess data for all the funds.
Now we have all that is needed to set up and solve the optimization problem with the CVXR package. The code is a one-to-one translation of the mathematical notation for the constrained optimization problem that we introduced earlier.
library(CVXR)
# define the parameters to be optimised (w are the weights for every fund in the matrix X)
w <- Variable(ncol(X))
# set the objective of the optimization problem: minimize the variance of the portfolio
# quad_form(w, covar) is just a way of computing the portfolio variance given the fund weights. It is equivalent to: t(w) %*% covar %*% w
objective <- Minimize(quad_form(w, covar))
# set the constrains of the optimization problem
c_positive <- w >= 0 # weights need to be positive
c_sum1 <- sum(w) == 1 # weights need to add up to 1
c_return <- t(w) %*% x == desired_daily_return # constrain the returns
# define the problem and ask CVXR to solve it
problem <- Problem(objective, constraints = list(c_return, c_positive, c_sum1))
result <- solve(problem)The solution to this constrained optimiazation allows us to find the point on the efficient frontier corresponding to the desired return level (\(r\) in the formulas) that we fix as constraint. If we were to repeat this process for multiple values of \(r\) we would end up drawing the efficient frontier. In the figure below, every red dot is a solution obtained for a different value of \(r\). The line connecting them corresponds to the efficient frontier drawn at the beginning of this article. The blue dots are the original funds from which the efficient portfolios are constructed.
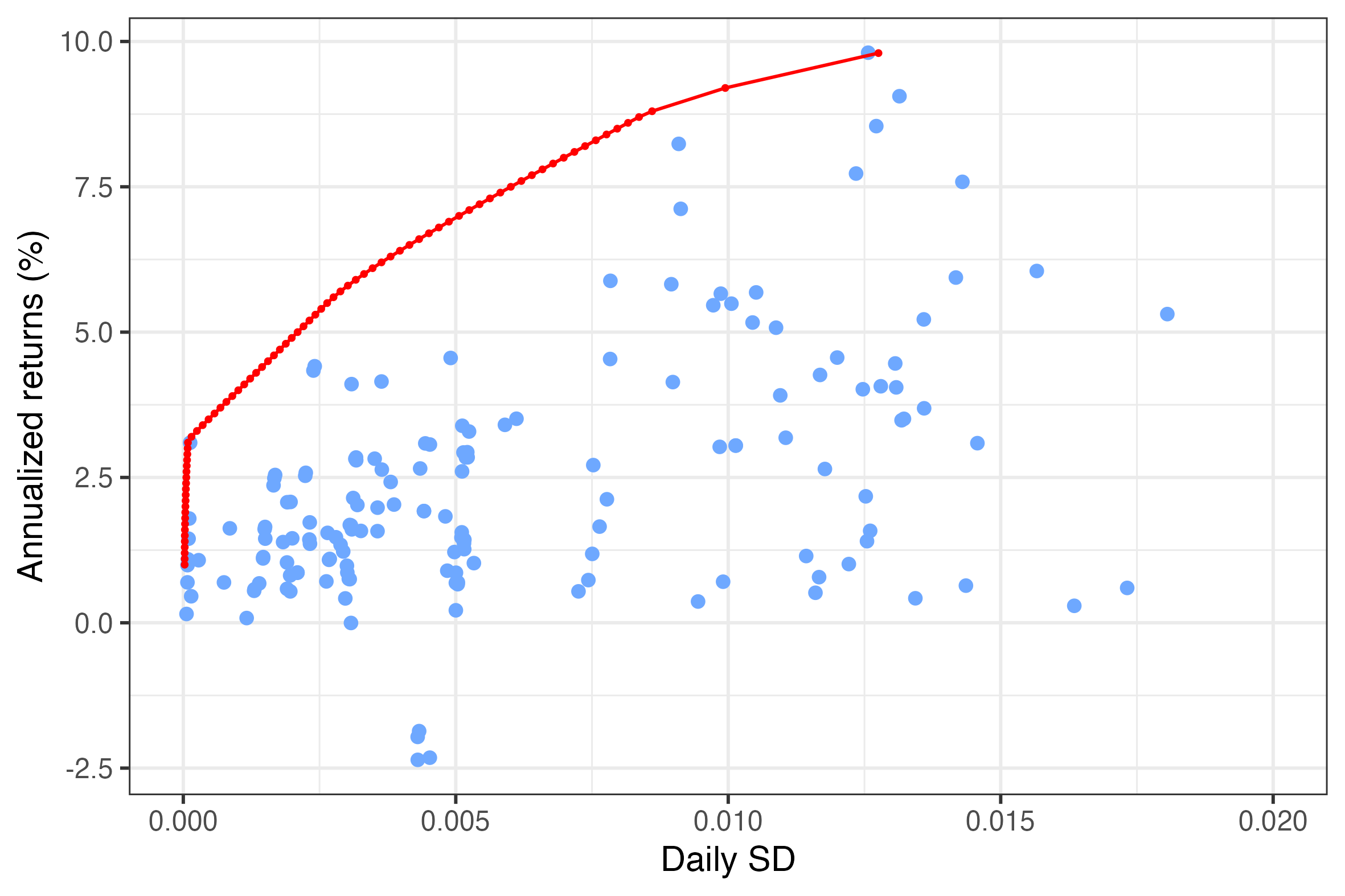
Figure 7: Optimal portfolios for different return levels
Conclusion: picking a portfolio
Now all that is left to do is pick the portfolio that best satisfies our return/risk preference. We have seen three approaches to derive or approximate an efficient portfolio. How much do they differ in terms of results? The table below compares the best portfolio standard deviation offered for any given level of expected returns. The lower the standard deviation the better (less volatile portfolio). Surprisingly, no single approach did significantly better than the others. The simulations yielded superior sets of portfolios for lower desired returns. This could be because we only used a subset of all the funds when solving with the convex optimization algorithm. The “improved” simulation approach fared slightly worse than the random one in two our of three cases. Perhaps, longer iterations are needed to compensate for the occasional “lucky strikes”. However, this shows that even the random approach is not too far off from the more complex mathematical optimization approach.
| Desired return (%) | SD of convex optimization | SD of random simulation | SD of improved simulation |
|---|---|---|---|
| 3 | 0.0098 | 0.0064 | 0.0055 |
| 5 | 0.0109 | 0.0060 | 0.0081 |
| 7 | 0.0091 | 0.0092 | 0.0097 |
Portfolio optimization based on MPT remains a valuable tool for investors, helping them make informed decisions and achieve a balance between returns and risk in their investment strategies. However, I reiterate that it is important for investors to consider other factors and seek professional advice to make well-rounded investment decisions.